Планирование в Go: часть III - Параллелизм (Concurrency)
О чем будем говорить: перевод статьи
Перевод сделан автором сайта goxpert.ru
- Статья обсуждает использование параллелизма в программировании на языке Go.
- Параллелизм может повысить производительность для рабочих нагрузок, связанных с процессором.
- Важно определить, подходит ли рабочая нагрузка для параллелизма и выбрать правильный тип рабочей нагрузки.
- Примеры алгоритмов и рабочих нагрузок демонстрируют различия в семантике и инженерные решения, которые необходимо учитывать.
- При использовании рабочих нагрузок, связанных с вводом-выводом, параллелизм не всегда приводит к значительному повышению производительности.
Введение
Когда я решаю проблему, особенно если это новая проблема, я изначально не думаю о том, подходит ли параллелизм или нет. Сначала я ищу последовательное решение и убеждаюсь, что оно работает. Затем, после удобочитаемости и технических обзоров, я начну задавать вопрос, является ли параллелизм разумным и практичным. Иногда очевидно, что параллелизм подходит, а в других случаях это не так однозначно.
В первой части этой серии я объяснил механику и семантику планировщика операционной системы, которые, на мой взгляд, важны, если вы планируете писать многопоточный код. Во второй части я объяснил семантику планировщика Go, которая, по моему мнению, важна для понимания того, как писать параллельный код в Go. В этом посте я начну сводить механику и семантику планировщиков OS и Go воедино, чтобы обеспечить более глубокое понимание того, что такое параллелизм, а что нет.
Целями этого поста являются:
- Дайть рекомендации по семантике, которую вы должны учитывать, чтобы определить, подходит ли рабочая нагрузка для использования параллелизма.
- Показать вам, как различные типы рабочих нагрузок меняют семантику и, следовательно, технические решения, которые вы захотите принять.
Что такое конкурирующий параллелизм (What is Concurrency)
Конкурирующий параллелизм(Concurrency) означает выполнение “не по порядку”. Берем набор инструкций, которые в противном случае выполнялись бы последовательно, и находим способ выполнять их не по порядку и при этом давать тот же результат. Для стоящей перед вами задачи должно быть очевидно, что выполнение вне очереди повысит ценность. Когда я говорю “ценность”, я имею в виду достаточный прирост производительности для снижения затрат на сложность. В зависимости от вашей проблемы выполнение вне очереди может быть невозможным или даже иметь смысл.
Также важно понимать, что сoncurrency - это не то же самое, что параллелизм( concurrency is not the same as parallelism ). Параллелизм(parallelism) означает выполнение двух или более инструкций одновременно. Это концепция, отличная от Конкурирующего параллелизма(concurrency). Параллелизм(Parallelism) возможен только тогда, когда вам доступны по крайней мере две аппаратных нити операционной системы (OS) и у вас есть по крайней мере 2 горутины, каждая из которых выполняет инструкции независимо в каждом аппаратной ните OS.
Рисунок 1: Параллелизм против параллелизма
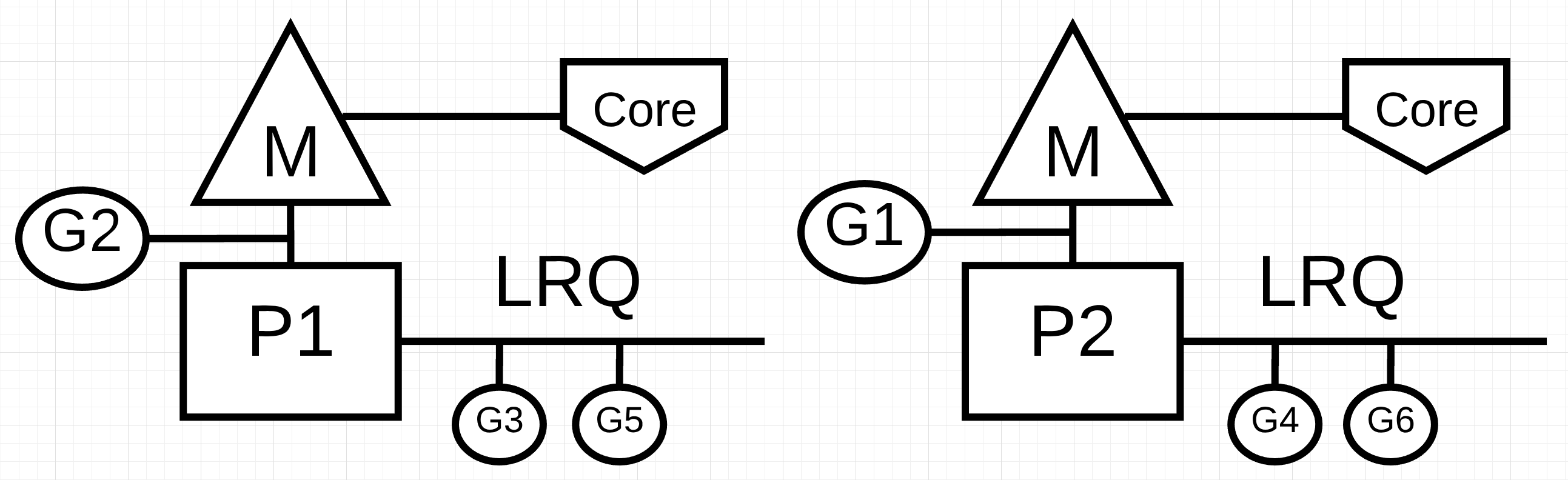
На рисунке 1 вы видите схему двух логических процессоров (P), каждый из которых имеет свой независимый поток операционной системы (M), подключенный к независимому аппаратному потоку (ядру - Core) на компьютере. Вы можете видеть, что две горутины (G1 и G2) выполняются параллельно, выполняя свои инструкции в соответствующей апаратной ните операционной системы одновременно. В каждом логическом процессоре три горутины по очереди совместно используют соответствующий поток операционной системы(OS thread). Все эти горутины работают одновременно, выполняя свои инструкции в произвольном порядке и распределяя время в потоке операционной системы(OS thread).
Проблема в том, что иногда использование конкурирующий параллелизма(concurrency) без параллелизма(parallelism) может фактически снизить пропускную способность. Что также интересно, так это то, что иногда использование конкурируещего параллелизма с параллелизмом не дает вам большего прироста производительности, чем вы могли бы ожидать в противном случае.
Рабочие нагрузки(Workloads)
Как узнать, когда выполнение вне очереди может быть возможным или иметь смысл? Понимание типа рабочей нагрузки, с которой сталкивается вы решаю вашу проблему(задачу), - отличное место для начала. Существует два типа рабочих нагрузок, которые важно понимать, когда речь заходит о конкурирующем параллелизме.
Привязка к процессору(CPU-Bound): Это рабочая нагрузка, которая никогда не создает ситуации, когда рабочие программы естественным образом переходят в состояния ожидания и выходят из них. Это работа, при которой постоянно выполняются вычисления. Поток, вычисляющий число Pi до N-й цифры, будет привязан к процессору.
Привязка к вводу-выводу(IO-Bound): Это рабочая нагрузка, из-за которой рабочие программы естественным образом переходят в состояния ожидания. Это работа, которая заключается в запросе доступа к ресурсу по сети, или выполнении системных вызовов в операционной системе, или ожидании наступления события. Подпрограмма, которой необходимо прочитать файл, будет привязана к вводу-выводу. Я бы включил события синхронизации (мьютексы, атомарные), которые заставляют горутину ждать, как часть этой категории.
При рабочих нагрузках с привязкой к процессору вам нужен параллелизм, чтобы использовать конкурирующий параллелизм. Один поток операционной системы / аппаратного обеспечения, обрабатывающий несколько горутин, неэффективен, поскольку горутины не переходят в состояния ожидания(waiting states) и из них не выходят в рамках своей рабочей нагрузки. Наличие большего количества горутин, чем потоков операционной системы / оборудования, может замедлить выполнение рабочей нагрузки из-за затрат на задержку (времени, которое требуется) при включении и выключении горутин в потоке операционной системы. Переключение контекста создает событие “Остановить мир Stop The World” для вашей рабочей нагрузки, поскольку ни одна из ваших рабочих нагрузок не выполняется во время переключения, когда это могло бы быть в противном случае.
При рабочих нагрузках, связанных с вводом-выводом, вам не нужен параллелизм для использования конкурирующего параллелизма. Один поток операционной системы / оборудования может эффективно обрабатывать несколько горутин, поскольку горутины естественным образом переходят в состояния ожидания(waiting states) и выходят из них в рамках своей рабочей нагрузки. Наличие большего количества рабочих горутин, чем потоков операционной системы / оборудования, может ускорить выполнение рабочей нагрузки, поскольку затраты на задержку при включении и выключении рабочих горутин в потоке операционной системы не приводят к возникновению события “Остановить мир”. Ваша рабочая нагрузка естественным образом прекращается, и это позволяет другой горутине эффективно использовать тот же поток операционной системы / оборудования вместо того, чтобы позволять потоку операционной системы / оборудования бездействовать.
Откуда вы знаете, сколько горутин на аппаратный поток обеспечивает наилучшую пропускную способность? Слишком мало горутин - и у вас больше времени простоя. Слишком много горутин - и у вас больше времени задержки переключения контекста. Вам стоит подумать над этим, но это выходит за рамки данного конкретного поста.
На данный момент важно просмотреть некоторый код, чтобы укрепить вашу способность определять, когда рабочая нагрузка может использовать конкурирующий параллелизм(concurrency), когда нет, и нужен ли обчный параллелизм(parallelism) или нет.
Добавление чисел (Adding Numbers)
Листинг 1
https://play.golang.org/p/r9LdqUsEzEz
1 | 36 func add(numbers []int) int { |
В листинге 1 в строке 36 объявлена функция с именем add, которая принимает набор целых чисел и возвращает сумму набора. Оно начинается в строке 37 с объявления v переменной, содержащей сумму. Затем в строке 38 функция линейно обходит коллекцию, и каждое число добавляется к текущей сумме в строке 39. Наконец, в строке 41 функция возвращает вызывающей стороне окончательную сумму.
Вопрос: является ли add функция рабочей нагрузкой, подходящей для выполнения не по порядку? Я полагаю, что ответ положительный. Набор целых чисел может быть разбит на меньшие списки, и эти списки могут обрабатываться одновременно. Как только все меньшие списки будут суммированы, набор сумм можно будет сложить вместе, чтобы получить тот же ответ, что и в последовательной версии.
Однако на ум приходит другой вопрос. Сколько списков меньшего размера следует создать и обрабатывать независимо, чтобы получить максимальную пропускную способность? Чтобы ответить на этот вопрос, вы должны знать, какую рабочую нагрузку add выполняет. Функция add выполняет нагрузку, связанную с ЦП, потому что алгоритм выполняет чистую математику, и ничто из того, что он делает, не приведет к переходу подпрограммы в естественное состояние ожидания. Это означает, что использование одной подпрограммы для каждого потока операционной системы / оборудования - это все, что необходимо для хорошей пропускной способности.
В листинге 2 ниже приведена моя параллельная версия add.
Примечание: Есть несколько способов и опций, которыми вы можете воспользоваться при написании параллельной версии add. На данный момент не зацикливайтесь на моей конкретной реализации. Если у вас есть более читаемая версия, которая работает так же или лучше, я был бы рад, если бы вы поделились ею.
Листинг 2
https://play.golang.org/p/r9LdqUsEzEz
1 |
|
В листинге 2 представлена addConcurrent функция, которая является параллельной версией add функции. Параллельная версия использует 26 строк кода в отличие от 5 строк кода для непараллельной версии. Кода много, поэтому я выделю только важные строки для понимания.
Строка 48: Каждая подпрограмма получит свой собственный уникальный, но меньший список номеров для добавления. Размер списка рассчитывается путем взятия размера коллекции и деления его на количество подпрограмм.
Строка 53: Для выполнения работы по добавлению создается пул подпрограмм.
Строка 57-59: Последняя подпрограмма добавит оставшийся список чисел, которых может быть больше, чем в других подпрограммах.
Строка 66: Сумма меньших списков суммируется в окончательную сумму.
Параллельная версия определенно сложнее последовательной, но стоит ли того сложность? Лучший способ ответить на этот вопрос - создать бенчмарк. Для этих тестов я использовал коллекцию из 10 миллионов чисел с отключенным сборщиком мусора. Существует последовательная версия, которая использует add функцию, и параллельная версия, которая использует addConcurrent функцию.
Листинг 3
1 | func BenchmarkSequential(b *testing.B) { |
В листинге 3 показаны тестовые функции. Вот результаты, когда для всех программ доступен только один поток операционной системы / оборудования. Последовательная версия использует 1 программу, а параллельная версия использует runtime.NumCPU или 8 программ на моей машине. В этом случае параллельная версия использует параллелизм без параллелизма.
Листинг 4
1 | 10 Million Numbers using 8 goroutines with 1 core |
Примечание: Запуск бенчмарка на вашем локальном компьютере сложен. Существует множество факторов, которые могут привести к тому, что ваши бенчмарки будут неточными. Убедитесь, что ваш компьютер простаивает настолько, насколько это возможно, и запустите бенчмарки несколько раз. Вы хотите убедиться, что видите согласованность результатов. Если инструмент тестирования дважды запускает бенчмарк, это дает ему наиболее согласованные результаты.
Тест, приведенный в листинге 4, показывает, что последовательная версия примерно на 10-13 процентов быстрее параллельной, когда для всех программ доступен только один поток операционной системы / оборудования. Это то, чего я ожидал, поскольку параллельная версия имеет накладные расходы на переключение контекста в этом единственном потоке операционной системы и управление подпрограммами.
Вот результаты, когда для каждой подпрограммы доступен отдельный поток операционной системы / оборудования. Последовательная версия использует 1 подпрограмму, а параллельная версия использует runtime.NumCPU или 8 подпрограмм на моей машине. В этом случае параллельная версия использует параллелизм с параллелизмом.
Листинг 5
1 | 10 Million Numbers using 8 goroutines with 8 cores |
Тест, приведенный в листинге 5, показывает, что параллельная версия примерно на 41-43 процента быстрее последовательной версии, когда для каждой подпрограммы доступен отдельный поток операционной системы / оборудования. Это то, чего я ожидал, поскольку все программы теперь работают параллельно, восемь программ выполняют свою параллельную работу одновременно.
Сортировка
Важно понимать, что не все рабочие нагрузки с привязкой к процессору подходят для параллелизма. В первую очередь это верно, когда очень дорого разбивать работу и / или объединять все результаты. Пример этого можно увидеть на примере алгоритма сортировки, называемого пузырьковой сортировкой. Посмотрите на следующий код, который реализует пузырьковую сортировку в Go.
Листинг 6
https://play.golang.org/p/S0Us1wYBqG6
1 | package main |
В листинге 6 приведен пример пузырьковой сортировки, написанный в Go. Этот алгоритм сортировки просматривает коллекцию целых чисел, меняя значения на каждом проходе. В зависимости от порядка расположения списка может потребоваться несколько проходов по коллекции, прежде чем все будет отсортировано.
Вопрос: является ли bubbleSort функция рабочей нагрузкой, подходящей для выполнения не по порядку? Я полагаю, что ответ отрицательный. Набор целых чисел можно разбить на меньшие списки, и эти списки можно сортировать одновременно. Однако после выполнения всей параллельной работы не существует эффективного способа объединить меньшие списки вместе. Вот пример параллельной версии пузырьковой сортировки.
Листинг 8
1 | func bubbleSortConcurrent(goroutines int, numbers []int) { |
В листинге 8 представлена bubbleSortConcurrent функция, которая является параллельной версией bubbleSort функции. Она использует несколько подпрограмм для одновременной сортировки частей списка. Однако у вас остается список отсортированных значений в виде фрагментов. Учитывая список из 36 номеров, разделенных на группы по 12, это будет результирующий список, если весь список не будет отсортирован еще раз в строке 25.
Листинг 9
1 | Before: |
Поскольку природа пузырьковой сортировки заключается в просмотре списка, вызов bubbleSort в строке 25 сведет на нет любые потенциальные выгоды от использования параллелизма. При пузырьковой сортировке использование параллелизма не приводит к увеличению производительности.
Чтение файлов
Были представлены две рабочие нагрузки, связанные с процессором, но как насчет рабочей нагрузки, связанной с вводом-выводом? Отличается ли семантика, когда программы естественным образом переходят в состояния ожидания и выходят из них? Рассмотрим рабочую нагрузку, связанную с вводом-выводом, которая считывает файлы и выполняет текстовый поиск.
Эта первая версия представляет собой последовательную версию вызываемой функции find.
Листинг 10
https://play.golang.org/p/8gFe5F8zweN
1 | 42 func find(topic string, docs []string) int { |
В листинге 10 вы видите последовательную версию find функции. В строке 43 объявляется переменная с именем found для подсчета количества раз, когда указанное topic встречается внутри данного документа. Затем в строке 44 документы повторяются, и каждый документ считывается в строке 45 с помощью read функции. Наконец, в строке 49-53 Contains функция из strings пакета используется для проверки, можно ли найти тему внутри коллекции элементов, прочитанных из документа. Если тема найдена, found переменная увеличивается на единицу.
Вот реализация read функции, которая вызывается find.
Листинг 11
https://play.golang.org/p/8gFe5F8zweN
1 | 33 func read(doc string) ([]item, error) { |
read Функция из листинга 11 начинается с time.Sleep вызова в течение одной миллисекунды. Этот вызов используется для моделирования задержки, которая могла бы возникнуть, если бы мы выполнили реальный системный вызов для чтения документа с диска. Постоянство этой задержки важно для точного измерения производительности последовательной версии find по сравнению с параллельной версией. Затем в строках 35-39 макет XML-документа, хранящийся в глобальной переменной, file преобразуется в значение struct для обработки. Наконец, коллекция элементов возвращается вызывающему абоненту в строке 39.
Теперь, когда установлена последовательная версия, вот параллельная версия.
Примечание: Есть несколько способов и опций, которыми вы можете воспользоваться при написании параллельной версии find. На данный момент не зацикливайтесь на моей конкретной реализации. Если у вас есть более читаемая версия, которая работает так же или лучше, я был бы рад, если бы вы поделились ею.
Листинг 12
https://play.golang.org/p/8gFe5F8zweN
1 | 58 func findConcurrent(goroutines int, topic string, docs []string) int { |
В листинге 12 представлена findConcurrent функция, которая является параллельной версией find функции. Параллельная версия использует 30 строк кода в отличие от 13 строк кода для непараллельной версии. Моей целью при реализации параллельной версии было контролировать количество подпрограмм, которые используются для обработки неизвестного количества документов. Моим выбором был шаблон объединения, при котором канал используется для подпитки пула подпрограмм.
Кода много, поэтому я выделю только важные строки для понимания.
Строки 61-64: Канал создается и заполняется всеми документами для обработки.
Строка 65: Канал закрыт, поэтому пул подпрограмм естественным образом завершается, когда обрабатываются все документы.
Строка 70: Создан пул подпрограмм.
Строка 73-83: Каждая подпрограмма в пуле получает документ из канала, считывает документ в память и проверяет содержимое на предмет соответствия теме. При обнаружении совпадения локальная найденная переменная увеличивается.
Строка 84: Сумма подсчетов отдельных подпрограмм суммируется в итоговый подсчет.
Параллельная версия определенно сложнее последовательной, но стоит ли того сложность? Лучший способ ответить на этот вопрос еще раз - создать бенчмарк. Для этих тестов я использовал коллекцию из 1 тысячи документов с отключенным сборщиком мусора. Существует последовательная версия, которая использует find функцию, и параллельная версия, которая использует findConcurrent функцию.
Листинг 13
1 | func BenchmarkSequential(b *testing.B) { |
В листинге 13 показаны тестовые функции. Вот результаты, когда для всех программ доступен только один поток операционной системы / оборудования. Последовательная использует 1 программу, а параллельная версия использует runtime.NumCPU или 8 программ на моей машине. В этом случае параллельная версия использует параллелизм без параллелизма.
Листинг 14
1 | 10 Thousand Documents using 8 goroutines with 1 core |
Тест, приведенный в листинге 14, показывает, что параллельная версия примерно на 87-88 процентов быстрее последовательной версии, когда для всех программ доступен только один поток операционной системы / оборудования. Это то, чего я ожидал, поскольку все программы эффективно используют единый поток операционной системы / оборудования. Естественное переключение контекста, происходящее для каждой подпрограммы в read вызове, позволяет со временем выполнять больше работы в одном потоке операционной системы / оборудования.
Вот эталон при использовании параллелизма с параллелизмом.
Листинг 15
1 | 10 Thousand Documents using 8 goroutines with 1 core |
Тест, приведенный в листинге 15, показывает, что добавление дополнительных потоков операционной системы / оборудования не обеспечивает повышения производительности.
Заключение
Целью этого поста было дать рекомендации по семантике, которую вы должны учитывать, чтобы определить, подходит ли рабочая нагрузка для использования параллелизма. Я попытался привести примеры различных типов алгоритмов и рабочих нагрузок, чтобы вы могли увидеть различия в семантике и различные инженерные решения, которые необходимо учитывать.
Вы можете ясно видеть, что при рабочих нагрузках, связанных с вводом-выводом, параллелизм не был необходим для значительного увеличения производительности. Что противоположно тому, что вы видели при работе с привязкой к процессору. Когда дело доходит до такого алгоритма, как пузырьковая сортировка, использование параллелизма усложнило бы работу без какого-либо реального повышения производительности. Важно определить, подходит ли ваша рабочая нагрузка для параллелизма, а затем определить тип рабочей нагрузки, который вы должны использовать с правильной семантикой.